외부 RAM에서 그래픽 실행하기
이 섹션은 아래에 소개된 일반적인 설정의 그래픽 성능을 계산하는 방법을 설명합니다. 예시는 외부 32비트 SDRAM에 저장된 16bpp 프레임 버퍼가 있는 1024x600픽셀의 24비트 RGB-TFT 고해상도 디스플레이입니다. 그래픽 애셋은 외부 OSPI NOR 플래시에 저장되어 있습니다.
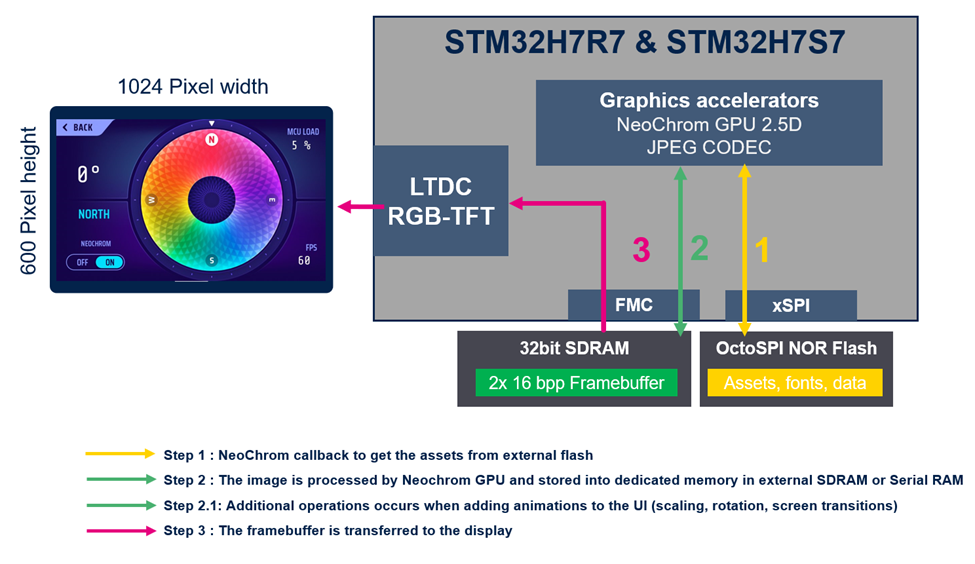
예시에 사용된 설정의 이미지
목표
- 개발자가 그래픽 사용자 인터페이스 애플리케이션을 위한 시스템 성능을 더 잘 이해하고 예측할 수 있도록 단계별 개요를 제공합니다.
- 선택한 디스플레이와 그 요구 사항이 정의되고 명시된 시스템에서 유지될 수 있는지 확인합니다.
- 정의된 하위 시스템 내에서 어느 정도 수준의 GUI를 개발할 수 있을지 파악합니다.
1단계: 디스플레이 사양
STM32H7S78 디스커버리 키트에 사용되는 디스플레이는 MB1860입니다. 디스커버리 키트의 BoM에 대한 링크는 여기에서 찾을 수 있습니다. 디스커버리 키트 디스플레이의 해상도는 이 예시에 사용된 해상도보다 낮은 800px x 480px입니다. 예시 디스플레이의 사양은 아래에서 확인할 수 있습니다:
- 디스플레이 높이: 600px
- 디스플레이 너비: 1024px
- 디스커버리 주사율: 60Hz
- 디스플레이 블랭킹 영역*: 일반적으로 최대 10%
*디스플레이 블랭킹은 비활성 픽셀의 합을 말합니다. 이 중 대부분은 LTDC의 포치에서 비롯됩니다.
2단계: 디스플레이 요구 사항 및 픽셀 클럭 계산
이 단계에서는 선택한 MCU와 메모리가 필요한 사양의 디스플레이를 작동시킬 수 있는지 파악하기 위해 디스플레이 요구 사항을 계산해야 합니다.
위에 명시된 디스플레이 크기에서 픽셀의 총 개수가 다음과 같음을 알 수 있습니다:
픽셀 높이 x 픽셀 너비 = 600px x 1024px = 614.400px
디스플레이의 주사율은 60Hz(1000ms / 60 = 16ms)이므로 LTDC는 프레임 버퍼를 가져와서 이를 약 16초마다 디스플레이로 보내야 합니다. 그러고 나면 다음 공식을 통해 60Hz(평균, 블랭킹 없이)에서 디스플레이가 업데이트된 상태를 유지하게 하는 데 필요한 시스템 (RAM) 대역폭을 찾아낼 수 있습니다:
디스플레이 픽셀 x 업데이트 빈도 x 프레임 버퍼 색 심도(RGB565)
614.400px x 60Hz x 16bpp = 589.824.000bits/sec = 589,82Mbit/sec
60Hz에서 디스플레이를 업데이트하는 데 필요한 픽셀 클럭은 아래 계산을 이용해 찾아낼 수 있습니다.
(픽셀의 총 개수 x 주사율 x (블랭킹% / 100 + 1)) / 1.000.000.
(614.400px x 60Hz x (10 / 100 + 1)) / 1.000.000 = 40,55MHz 픽셀 클록
Caution
LTDC에서 지원되는 최대 픽셀 클럭을 초과하지 않는 것이 중요합니다. 다양한 구성에서 지원되는 최대 픽셀 클럭에 대한 개요는 LTDC 애플리케이션 노트, AN4861,를 참조하세요. STM32H7R/S의 최대 픽셀 클럭에 대한 개요는 표 13에서 확인할 수 있습니다.
STM32H7R/S에 대해 지원되는 최대 픽셀 클럭에 대한 개요는 아래 삽입된 LTDC 애플리케이션 노트의 표 13에서 확인할 수 있습니다.
STM32H7R3/7S3 및 STM32H7R7/7S7에서 지원되는 최대 픽셀 클럭
3단계: 프레임 버퍼 및 메모리 전략
이 예제에서는 이중 프레임 버퍼 전략을 사용하여 100MHz에서 실행되는 32비트 와이드 FMC 인터페이스에 연결된 외부 32비트 SDRAM을 사용합니다. 또는 대안으로 200MHz DTR에서 16비트 SDRAM, 하이퍼 RAM 및 직렬 PSRAM 등의 4/8/16비트 직렬 RAM을 사용할 수도 있습니다.
모든 외부 메모리는 작동을 시작하기 위해 약간의 추가 사이클이 필요하며 이 예제에서는 SDRAM이 최대 80%의 효율성으로 작동한다고 가정하겠습니다.
4단계: 프레임 버퍼 성능
이론적인 RAM 처리량은 프론트(front) 버퍼와 백(back) 버퍼가 서로 다른 RAM 뱅크에 배치된 경우 다음 방정식을 통해 구합니다:
인터페이스 너비 x 인터페이스 주파수 = Mbit/sec
32bit x 100MHz = 3.200Mbit/sec = 400MB/Sec
하지만 이 처리량은 100% 효율성을 발휘하는 RAM을 기준으로 합니다. 3 단계에서 예상한 효율성을 고려하면 실제 처리량은 다음과 같습니다:
3.200Mbit/sec x 0.8 = 2.560Mbit/sec = 320Mbytes/sec
5단계: 디스플레이 업데이트 후 남은 대역폭 계산하기
앞에서 디스플레이에 589,82Mbit/sec가 필요하며 외부 RAM의 처리량이 2.560Mbit/sec라는 것을 확인했습니다. 이제 스크린 렌더링/애니메이션에 사용할 수 있는 대역폭이 얼마나 남았는지 확인해 보겠습니다.
2.560Mbit/sec – 589,82Mbit/sec = 1.970,18Mbit/sec = 246,27MBytes/sec
전체적으로 예제 시스템은 디스플레이를 지속적으로 업데이트할 수 있으며, 무엇보다 최대 1.970Mbit/sec의 대역폭이 남아 있어 추가적인 애니메이션과 UI 계층에 사용할 수 있습니다.
6단계: UI 렌더링 성능(GUI FPS)
이 UI 사례에서는 60FPS GUI 렌더링을 목표로 합니다. 이는 시스템이 16ms 내에 새로운 프레임을 렌더링해 전송해야 한다는 뜻입니다. 또한 전체적으로 매끄러운 사용자 경험을 보장하기 위해 일부 고급 UI 애니메이션의 경우 30FPS까지 떨어지는 것을 허용할 수 있습니다.
프레임 버퍼 슬라이스당 프레임 버퍼 성능을 계산해 보겠습니다. 이는 각 프레임 내에 얼마나 많은 Mbit를 렌더링할 수 있는지를 보여줍니다(16ms당). 우선 남은 프레임 버퍼 대역폭(1.970Mbit/sec)을 사용해 60FPS로 나눕니다.
1.970Mbit/sec / 60FPS = 프레임당 32,8Mbit(60FPS에서 약 16ms마다).
이는 UI를 렌더링 및 업데이트하기 위한 RAM 처리량이 16ms당 32.8Mbit라는 뜻입니다.
시작 부분에 있는 설정 이미지에서 2단계는 UI의 변경/업데이트를 위한 추가 렌더링이 가능함을 보여줍니다. 프레임 버퍼는 16bpp이므로 프레임 버퍼상의 모든 작업은 16bpp에서 이루어집니다. 따라서 프레임 버퍼에 픽셀을 쓰려면 16비트의 SDRAM 대역폭이 필요합니다. 픽셀을 혼합해야 할 경우 먼저 NeoChrom GPU가 프레임 버퍼에서 픽셀을 읽습니다. 픽셀이 혼합된(수정된) 후에 다시 프레임 버퍼에 쓰여집니다. 즉, 읽기-수정-쓰기 작업을 위해서는 시스템이 16bit를 2번 전송해야 하므로 아래 이미지에서 볼 수 있듯이 16bit + 16bit = 32bit의 SDRAM 대역폭을 사용해야 한다는 뜻입니다.
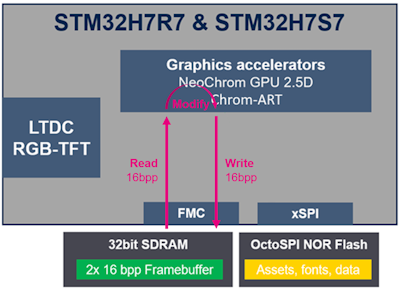
프레임 버퍼에서의 읽기-수정-쓰기 작업의 이미지
이제 각 프레임 내의 한 작업에서 수행할 수 있는 픽셀의 수는 몇 개인지 계산할 수 있습니다.
32,8Mbit/frame / 16bpp = 2,05Mpixels
기준점을 제시하기 위해 각 프레임 내에서 수행할 수 있는 전체 화면 작업 건수를 계산합니다.
2,05Mpixels / 614.000px = 3,34회
예를 들어 전체 화면 크기의 상자 하나를 그린 다음 이를 다른 상자와 혼합할 수 있습니다(16bpp 쓰기 + 16bpp 읽기 + 16bpp 쓰기). 이를 화면의 17%(34%/2)를 차지하는 세 번째 상자와 추가로 혼합할 수 있습니다.
6단계를 시작하면서 언급했듯이 일부 고급 UI 애니메이션의 경우 30FPS로 떨어지는 것을 받아들일 수 있습니다. 이는 60FPS에 비해 이용 가능한 대역폭이 2배라는 뜻이므로 각 프레임 내에서 수행할 수 있는 전체 화면 작업의 건수는 다음과 같습니다:
3,34 x 2 = 6,68회
각 프레임 내에서 수행할 수 있는 전체 화면 작업의 건수를 명백히 밝힐 수는 없습니다. UI의 복잡성에 따라 변동의 폭이 크기 때문입니다. 게다가 프레임 버퍼 외의 다른 것에 외부 RAM이 필요한지를 고려하는 것이 중요합니다. 하지만 다수의 애플리케이션에 대한 합리적인 가이드라인은 최소한 3번 이상이어야 한다는 것입니다.
구체적인 예시와 비교하자면 STM32H7S78-DK는 200MHz DTR에서 800x480 RGB TFT 디스플레이를 작동시키며 외부 16비트 직렬 PSRAM에는 16비트 프레임 버퍼가 있습니다(효율성이 100%일 경우 이론적으로 800MB/S). 이 유형의 메모리 프로토콜은 초기에 더 많은 사이클을 사용하므로 SDRAM에 비해 메모리 초기화 효율성이 낮습니다(직렬 RAM 성능에 대한 자세한 내용은 AN6062 참조). 위의 예제와 계산은 이 해상도에서는 가장 복잡한 UI라도 60FPS를 유지하면서 렌더링할 수 있음을 보여줍니다.
또 다른 참조는 2가지의 서로 다른 RAM 및 플래시 메모리 주파수와 복잡한 UI를 보여주는 TouchGFX 데모입니다.
Further reading
참고
위의 계산은 RAM 대역폭에만 중점을 두었으며 가용 컴퓨팅 성능을 고려하지 않은 것임에 유의하세요. 또한 RAM 효율성에 대한 가정에 기반해 계산한 값입니다. 이러한 가정은 임의적인 것은 아니지만 여전히 가정입니다.
이러한 한계에도 불구하고 예제의 절차는 여전히 가능한 성능 수준을 보여줍니다.
용어집
- 읽기-수정-쓰기: 메모리 위치가 읽히고 수정되고 다시 쓰여지는 프로세스입니다.
- 픽셀 클럭: 픽셀이 디스플레이로 전송되는 빈도로 스크린의 주사율과 해상도를 결정합니다. 이는 디스플레이 컨트롤러가 픽셀 데이터를 디스플레이 패널로 보내는 속도를 정의합니다.
- 프레임 버퍼: 디스플레이를 구동하는 비트맵이 포함된 RAM의 한 영역입니다. 프레임 버퍼는 디스플레이 컨트롤러에서 읽어오는 픽셀 값을 저장합니다. 렌더링 작업은 프레임 버퍼에 수행됩니다.
- 블랭킹: 디스플레이 블랭킹은 비활성 픽셀의 합을 말합니다. 이 중 대부분은 LTDC의 포치에서 비롯됩니다.
- FMC: Flexible Memory Controller입니다. SRAM, NOR, NAND, SDRAM 등 다양한 메모리 유형과 CPU 간의 인터페이스를 관리하는 하드웨어 구성 요소입니다. 이 예시에서 이는 외부 SDRAM에 사용됩니다.
- XSPI: 확장-SPI 인터페이스입니다. 주변 디바이스와의 향상된 통신을 위해 더 높은 데이터 속도와 추가적인 기능을 지원하는 고급 버전의 SPI입니다. 이 예시에서 이는 외부 NOR 플래시에 사용됩니다. 자세한 내용은 wiki에서 참조하세요.
- 메모리 프로토콜 오버헤드: 오류 확인, 핸드셰이킹, 어드레싱 등의 작업을 포함한 메모리와 프로세서 간의 통신 및 데이터 전송을 관리하는 데 필요한 추가적인 시간과 리소스입니다. 이 오버헤드는 전반적인 시스템의 성능에 영향을 미칩니다.
- DTR: 이중 전송 속도. 데이터가 상승 클럭 엣지와 하강 클럭 엣지 모두에서 전송됩니다. 따라서 대역폭이 두 배입니다.